在许多企业工作流中,分类听起来很简单。
一封电子邮件到达。
一个工单被创建。
一项请求需要被路由。
乍看之下,这似乎是一个直接明了的模型问题:
- 对输入进行分类
- 分配一个类别
- 触发下一步操作
但在实践中,企业级分类很少仅仅关乎模型的准确率。
它还涉及:
- 延迟
- 成本
- 治理
- 数据敏感性
- 运维适配性
- 降级行为
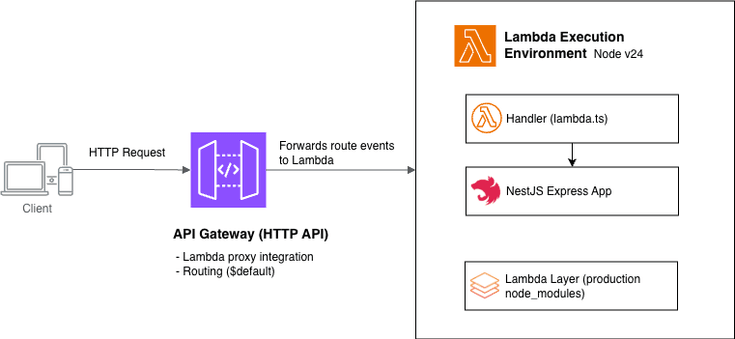
正是在这一点上,架构变得比模型本身更为重要。
在本文中,我想分享一种在企业环境中思考分类系统的实用方法:
- 何时使用本地或部门级模型更为合理
- 何时Azure AI / 云模型是更优选择
- 以及一个智能路由层如何彻底改变整体设计
分类问题无处不在
分类出现在比我们通常意识到更多的场景中:
- 支持工单分类
- 邮件分诊
- 事件优先级排序
- 请求类型识别
- 业务工作流路由
- 文档打标
- 政策或合规性标记
多年来,常见的设计模式非常简单:
输入 → 模型 → 标签
在某些情况下,这种模式仍然有效。
但一旦引入企业环境的约束条件,事情就变得更加微妙。
并非每个请求都需要同一个模型。
并非每个分类任务都需要同等程度的推理能力。
也并非每个输入都应仅仅因为存在云模型就跨越部门边界。
本地模型与 Azure AI:这不是非此即彼的选择
最有用的思维转变之一是:
问题不在于哪个模型更好。
问题在于每个模型在架构中的合适位置。
本地 / 部门级模型
当分类问题具有以下特征时,本地模型通常是更优选择:
- 重复性强
- 高吞吐量
- 可预测
- 范围狭窄
- 从数据处理角度看具有敏感性
示例包括:
- 路由常见的内部请求类型
- 标记运维告警
- 对结构化或半结构化的内部邮件进行分类
- 识别一组稳定的部门类别
为何本地模型在此类场景中表现良好
它们可以提供:
- 更低的延迟
- 更低的成本
- 更强的数据本地化控制
- 更简单的运维边界
- 对已知模式的良好性能
换句话说,本地模型通常非常适合稳定的运维分类任务。
Azure AI 在何处创造更大价值
当问题的可预测性较低时,Azure AI 或基于云的模型就变得更加有用。
这种情况通常发生在输入具有以下特征时:
- 模糊不清
- 非结构化
- 跨职能
- 高度依赖上下文
- 随时间变化
示例包括:
- 包含多重意图的请求
- 信息不完整的工单
- 需要上下文解读的电子邮件
- 分类依赖于检索知识的工作流
- 在路由前需要推理能力的场景
为何 Azure AI 在此处有所帮助
云模型能够提供:
- 更广泛的语言理解能力
免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。