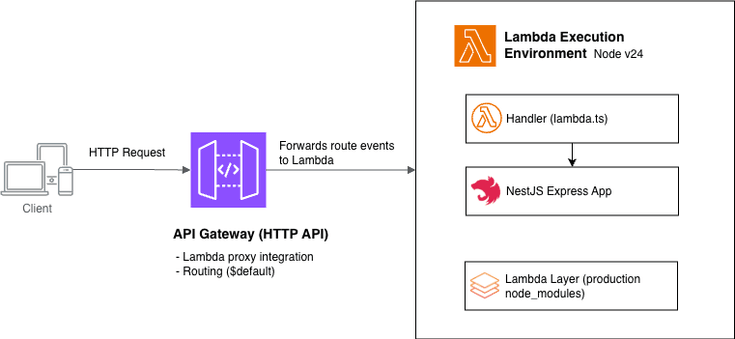
每次 AI 编程会话,我的智能体都会犯同样的错误。
将 DbContext 设为单例 —— 状态被破坏,调试花了 15 分钟。又来了。 用了 ILogger 而不是 IMLog —— 租户上下文丢失。又来了。 项目引用路径错误 —— 构建失败。又来了。
我有 500 条记忆笔记,但我的智能体仍是个拿着更大笔记本的初级开发者。
于是我做了点不一样的东西。
AI 记忆的问题所在
所有 AI 记忆工具 —— Mem0、Letta、Zep —— 存储的都是事实。会话越多,条目就越多,消耗的 token 就越多,成本也就越高。它们只是给你的智能体配了一个更大的笔记本。
但关键在于:笔记本并不能让你变得经验丰富。
一个拥有 500 条笔记的初级开发者,仍然是初级开发者。而一个掌握 15 条原则的中级开发者,却理解事情为何如此运作。两者的区别不在于记住多少内容,而在于能否归纳总结。
初级(500 条笔记):
“DbContext 单例导致了 bug”
“HttpClient 单例导致了内存泄漏”
“SmtpClient 单例导致了状态破坏”
→ 遇到 RedisConnection 单例 → 无匹配项 → 再次犯错
中级(1 条原则):
“有状态对象必须限定作用域,绝不能设为单例”
→ 遇到 RedisConnection 单例 → 匹配成功 → 避免错误
这正是“经验引擎”(Experience Engine)所做的事。它不会存储更多事实,而是将事实演化为原则,然后删除原始事实。
工作原理
当你使用任何 AI 智能体编程时(Claude Code、Gemini CLI、Codex CLI),“经验引擎”会在后台静默运行:
在每次编辑/编写/执行 Bash 命令之前:
一个钩子会查询经验存储:“我以前是否见过这个错误?” 如果答案是肯定的,它会直接将警告注入智能体的上下文中:
⚠️ [经验 - 高置信度 (0.85)]:有状态对象必须限定作用域,绝不能设为单例。
上次使用 SingleInstance 导致 DbContext 出现状态破坏。
智能体会读取该警告并避免犯错,全程无需人工干预。
每次会话结束后:
一个提取器会扫描会话记录,识别错误模式:
- 重试循环(同一工具调用 3 次以上)
- 用户纠正(“不对,不是那个”、“错了”、“撤销”)
- 测试失败 → 修复的循环
- Git 回退操作
每个检测到的错误都会被提取为结构化的问答条目,并存入向量数据库。
每周自动执行:
演化引擎启动:
- 升级:被确认 3 次以上的条目从缓存移至行为规则
- 抽象:将 3 个以上相似条目聚合成一条通用原则
- 降级:被忽略 3 次以上的条目会被降低优先级
- 归档:90 天未使用的条目会被清理
结果就是:随着能力提升,记忆反而不断精简。
四层架构
T0 原则层 (约 400 个 token)—— 通用规则,始终加载
“有状态对象必须限定作用域,绝不能设为单例”
T1 行为层 (约 600 个 token)—— 具体反射规则,始终加载
“当使用 DbContext 和依赖注入时 → 必须首先检查生命周期”
T2 问答缓存层 (语义检索) —— 详细问答,在匹配时检索
问:“为何不能用单例?” → 答:“会导致跨请求的状态破坏”
T3 原始层 (暂存区) —— 未经处理的错误,保留 30 天
生命周期:T3 → 提取 → T2 → 升级(3 次确认后…)
免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。