2026年4月 · 懒人开发者 第5期
在第4期中,我用7天时间构建了 FeedMission。用户反馈开始涌入。起初,这些反馈很棒。但一旦数量堆积起来,另一个问题就浮现了。“请添加深色模式。”“晚上看伤眼睛。”“加个背景颜色选项吧。”三个人说了三种不同的话,但诉求其实是一样的。当反馈只有10条时,手动归类还行得通;但超过50条后,光是阅读它们就会耗尽你的时间。
我问了克劳德(Claude):“你能自动将相似的反馈归类吗?”答案是“嵌入向量”(embeddings)。
快速概览
- 使用 Voyage AI 将反馈文本转换为包含1024个数字的数组(即嵌入向量)
- 同时使用 Claude Haiku 分析情感得分(范围从 -1.0 到 1.0)
- 在 PostgreSQL 上启用 pgvector 扩展,用于向量存储和相似性搜索
- 余弦相似度 ≥ 0.85 视为同一组;低于该阈值则创建新组
- 当某个组的反馈数量增长时,克劳德会自动重新生成该组的名称和摘要
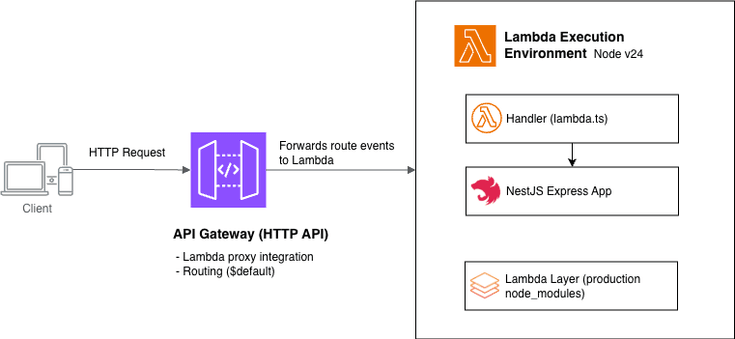
- 整个处理流程通过 after() 模式在后台运行
- 全部逻辑仅用188行代码写在 clustering.ts 文件中
“将相似的反馈归类”——但怎么做?
“请添加深色模式”和“晚上看伤眼睛”这两个句子没有任何相同的词,但它们表达的是同一个需求。你怎么让计算机理解这一点?办法是把句子转换成1024个数字。语义相近的句子会产生数值相近的向量。这就像外卖应用一样——搜索“深夜想吃点东西”,会同时返回炸鸡和猪蹄。它靠的是语义匹配,而不是字面关键词匹配。
“为什么不直接把两条反馈发给克劳德,问它们是否相似呢?”当然可以这么做。但如果有一百条反馈,就需要进行4950次两两比较。为每一对都调用克劳德 API,在时间和成本上都是不可行的。而使用嵌入向量,只需一次性生成向量,后续的比对由数据库通过数学运算完成。计算数字之间的距离只需几毫秒。
不过,嵌入向量并非万能。它在处理数字时表现较弱。“我需要3个按钮”和“我需要30个按钮”含义完全不同,但它们的嵌入向量坐标却几乎一样。否定句也有类似问题。“深色模式很棒”和“深色模式很糟糕”在向量空间中位置相近。我清楚这一点。但考虑到用户反馈的特性,这类情况并不常见。先快速搭建一个能覆盖80%场景的结构,等实际问题出现时再处理剩下的20%。
我第一次使用 Voyage AI 生成嵌入向量
// lib/ai/embeddings.ts
const response = await fetch('https://api.voyageai.com/v1/embeddings', {
body: JSON.stringify({
model: 'voyage-3-lite',
input: ["请添加深色模式"],
}),
})
// → [0.0234, -0.0891, 0.0412, ...] (1024个数字)
我同时使用 Claude Haiku 进行情感分析。“请
免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。