




欢迎来到 Apache Kafka 的世界,这是一个强大的工具,可以重塑我们处理实时数据的方式。今天,我们将揭秘 Kafka 是什么,以及它为何成为现代数据处理的基石。
想象一个繁华的城市,信息不断流动。Apache Kafka 就像这座城市的中枢神经系统,旨在轻松高效地处理这种海量数据流。Kafka 起源于 2011 年的 LinkedIn,后来成为 Apache 软件基金会下的一个开源项目,是一个分布式流媒体平台。
但这是什么意思呢?简单来说,Kafka 允许您发布和订阅记录流,可靠地存储这些记录,并在发生时对其进行处理。这就像拥有一个永不休息的超高效邮局,不断对邮件进行分类并将其发送到需要去的地方。

在我们这个数据驱动的世界里,高效处理实时数据的能力至关重要。Kafka 在这方面表现出色。它被数千家公司(包括 Netflix、Uber 和 Twitter 等巨头)用来处理流数据,用于实时分析、监控和许多其他应用。
Kafka 的稳健性、可扩展性和容错性使其成为处理大量数据流不可或缺的工具,确保企业能够快速有效地做出数据驱动的决策。
Kafka 架构和主要元素
让我们深入了解 Apache Kafka 的架构。我们将探索其关键组件并了解它们如何协同工作。
从本质上讲,Kafka 的设计目标是强大、可扩展且具有容错能力。它建立在分布式架构上,这意味着它的组件分布在不同的机器上,从而确保高可用性和弹性。
Kafka 生态系统由几个关键组成部分组成:
- 生产者:这些是向 Kafka 主题发布记录的数据源。可以将它们视为消息系统中的发送者。
- 消费者:他们订阅主题并处理已发布的记录。在我们的比喻中,他们就是接收者。
- Broker:这是 Kafka 的核心。Kafka 集群由多个 Broker 组成,用于维持负载平衡和管理数据。关于 Broker 的两点评论是,它们是有状态的,并且是 Kafka 中的可扩展性单元
- 主题:主题是发布记录的类别或源。Kafka 中的主题分为多个分区,以实现可扩展性和并行处理。
- 分区:每个分区都是一个有序的、不可变的记录序列,会不断追加。分区允许 Kafka 并行处理,因为每个分区都可以独立使用。
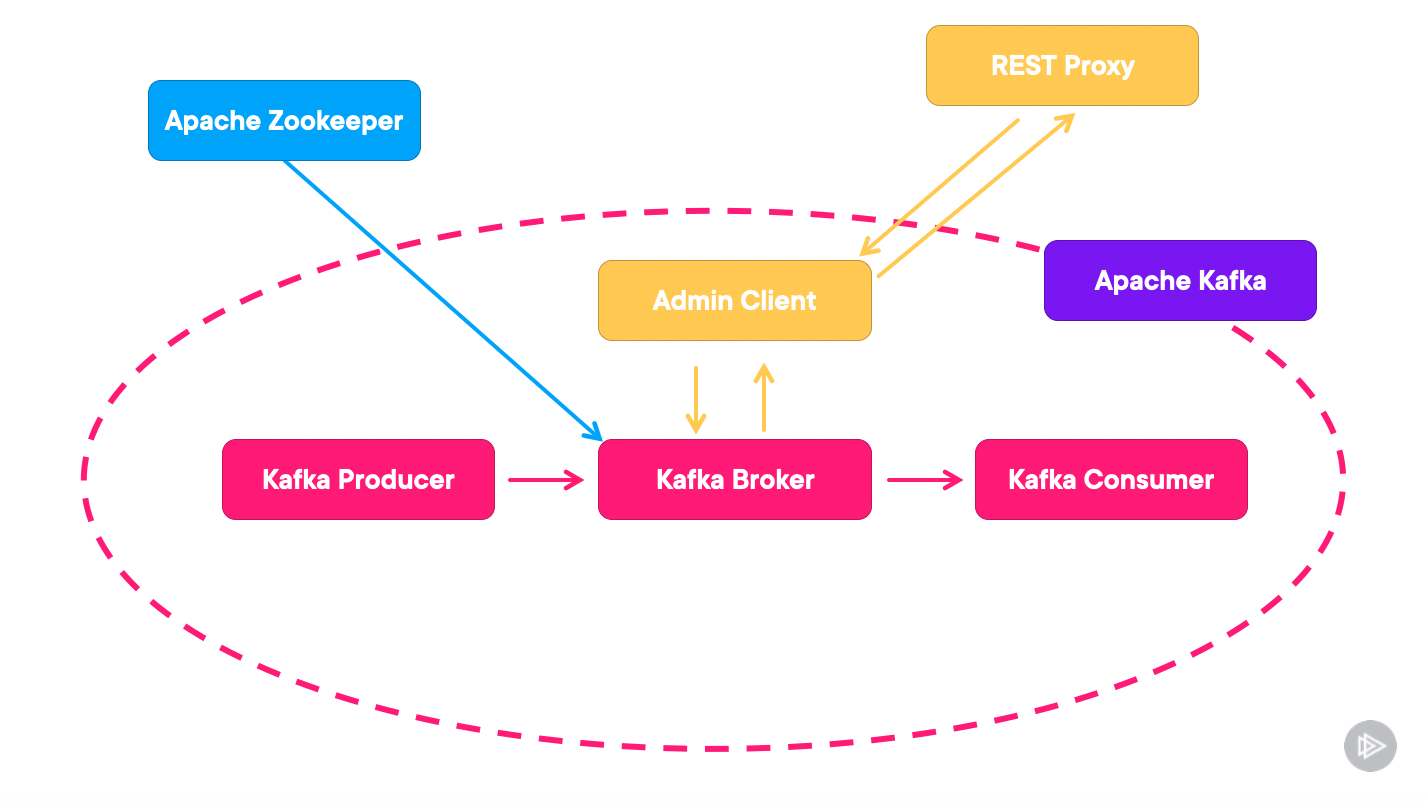
想象一下 Kafka 是一个高效的邮件系统。生产者就像发件人一样,将信件(消息)投递到邮局(经纪人)。每封信件都会被分类到特定的邮政信箱(主题)中,并进一步组织到隔间(分区)中。然后,消费者从这些隔间中收集信件,确保高效有序的处理。
让我们看看如何使用 Docker 设置基本的 Kafka 环境。我们将部署一个带有两个代理和 Zookeeper 的 Kafka 集群,Kafka 使用它进行集群管理和协调。
# docker-compose.yml for Kafka
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: kafka
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
depends_on:
- zookeeper
kafka2:
image: wurstmeister/kafka
ports:
- "9093:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: kafka2
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
depends_on:
- zookeeper
此 `docker-compose.yml` 文件设置了一个基本的 Kafka 环境。我们有 Zookeeper(对于管理 Kafka 集群至关重要)和两个 Kafka 代理(用于处理消息)。每个代理都暴露在不同的端口上,并且它们配置为连接到 Zookeeper 服务。
通过此设置,您将获得公司用于管理大量数据流的微型版本。Kafka 的架构旨在处理高吞吐量和低延迟,非常适合实时数据处理。
Kafka 与其他系统
在数据流和消息代理领域,Apache Kafka、Apache Pulsar 和 RabbitMQ 是杰出的参与者。让我们简单比较一下它们。
Kafka 与 Pulsar
Kafka 以高吞吐量和高可靠性而闻名,非常适合大规模消息处理。另一方面,Apache Pulsar 提供了类似的功能,但更注重多租户和地理复制,使其适用于复杂的分布式系统。
Kafka 与 RabbitMQ
RabbitMQ 以其简单易用而闻名,在传统消息传递和队列处理方面表现出色,通常适用于规模较小或不太复杂的应用程序。Kafka 具有分布式特性和高耐用性,更适合大规模事件流和日志记录。
代码:生产者和消费者
让我们通过生产者和消费者的基本 Java 代码示例深入了解 Apache Kafka 的实用方面。我们还将介绍关键的配置设置。
Kafka 生产者
Kafka 生产者将记录发送到主题。这是一个简单的 Java 示例(您也可以简单地使用 NodeJS 或 Python):
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class SimpleProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
try {
producer.send(new ProducerRecord<>("test", "Hello, Kafka!"));
} finally {
producer.close();
}
}
}
此生产者连接到在localhost:9092上运行的 Kafka ,向“测试”主题发送一条简单消息。关键配置包括服务器详细信息以及键和值的序列化器。
Kafka 消费者
现在,让我们看一下 Kafka 消费者,它从主题读取消息:
import org.apache.kafka.clients.consumer.*;
import java.util.Collections;
import java.util.Properties;
public class SimpleConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test"));
try {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
} finally {
consumer.close();
}
}
}
消费者连接到同一个 Kafka 集群并监听“测试”主题。这里的关键配置包括服务器详细信息、消费者组 ID 以及键和值的反序列化器。消费者组概念允许 Kafka 在多个消费者之间分配消息消费。
了解配置设置
在这两个示例中,bootstrap.servers指定要连接的 Kafka 代理。对于生产环境,这将是一个包含多个代理的列表,以实现容错。
由于 Kafka 在字节数组中存储和传输消息,因此生产者中的 key.serializer和value.serializer以及消费者中对应的反序列化器负责处理数据与字节之间的转换。
消费者中的group.id配置了该消费者属于哪个消费者组。当从同一分区消费消息时,Kafka 会使用它来进行负载平衡并将每条消息传递给组中的一个消费者。
这些设置只是冰山一角。Kafka 提供了大量配置来微调性能、安全性和可靠性,使其能够适应各种用例。
Kafka 3 亮点
Apache Kafka 3.0 引入了一项突破性转变,即转向无 Zookeeper 的架构,即 KRaft(Kafka Raft)。这一转变标志着 Kafka 演进的关键时刻,有望打造一个更加精简、高效和可扩展的平台。
KRaft 消除了 Kafka 对 Zookeeper(用于管理集群元数据和协调的单独服务)的历史依赖。通过将 Raft 共识协议直接集成到 Kafka 中,KRaft 简化了整体架构并提高了运营效率。
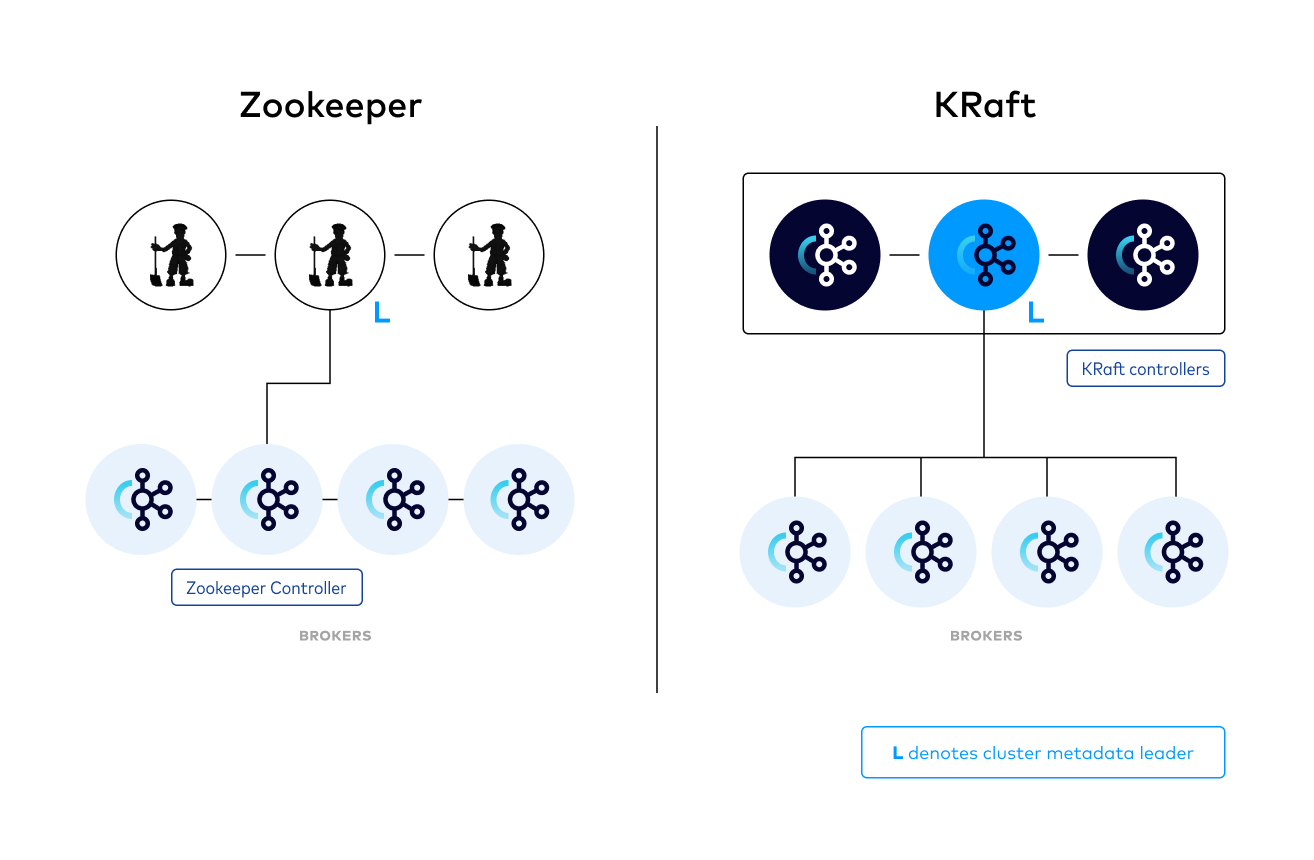
资料来源:https://developer.confluent.io/learn/kraft/
这一转变带来了几个主要好处:
- 简化操作:没有Zookeeper,Kafka的部署和管理变得更加简单,降低了运行Kafka集群的复杂性。
- 提高性能: KRaft 消除了与外部 Zookeeper 集群通信的需要,从而降低了控制器操作的延迟。
- 增强的可扩展性和可靠性: Kafka 内部的直接控制增强了平台的可扩展性和可靠性,为不受外部依赖限制的未来增强奠定了基础。
在使用 Zookeeper 的传统 Kafka 设置中,元数据管理是一个外部过程,增加了复杂性和潜在故障点。然而,KRaft 模式将这个过程内部化,从而形成一个更精简、更有凝聚力的系统。虽然基于 Zookeeper 的 Kafka 经过长时间的稳健和充分测试,但 KRaft 承诺将简化 Kafka 生态系统,使其更灵活,更能适应未来的需求。
挑战和最佳实践
实施 Kafka(尤其是对于初学者而言)可能会带来诸多挑战,例如管理数据一致性、理解分区策略以及处理集群可扩展性。最佳实践包括:
仔细规划:了解您的数据以及它如何流经 Kafka 主题至关重要。
监控和管理:定期监控Kafka的性能并有效地管理资源。
备份和灾难恢复:始终有一个数据备份和灾难恢复计划。
结论
Apache Kafka 不仅仅是一个消息系统,还是一个处理实时数据流的综合平台。它在医疗和银行等关键领域的应用凸显了其可靠性和效率。Kafka 3 转向无 Zookeeper 架构,标志着向更加精简和高效的未来迈出了重要一步。
对于初次接触 Kafka 的新手来说,请记住,旅途与目的地一样值得。随着 Kafka 社区的不断壮大和文档的丰富,掌握这一强大的工具是一个可以实现的目标。
进一步学习
为了加深你对 Kafka 的了解,请探索以下资源:
免责声明:本内容来源于第三方作者授权、网友推荐或互联网整理,旨在为广大用户提供学习与参考之用。所有文本和图片版权归原创网站或作者本人所有,其观点并不代表本站立场。如有任何版权侵犯或转载不当之情况,请与我们取得联系,我们将尽快进行相关处理与修改。感谢您的理解与支持!












