原始数据无法赢得模型竞赛。特征工程才是关键。当你的原始数据是分布在多个来源中的数百亿行记录时,你不可能仅仅在笔记本环境中运行潘达斯(Pandas)库就草草了事。
在本教程中,我将演示如何在 微软 Azure databricks 上构建生产级的特征工程流水线,使用的技术包括:
- 阿帕奇 Spark:用于大规模分布式数据转换
- Delta Lake:用于提供具有原子性、一致性、隔离性和持久性(ACID)保证的可靠、版本化特征存储
- MLflow:用于追踪特征流水线的运行、参数以及基于这些特征训练的模型
本案例是一个客户流失预测系统,但其所采用的模式适用于任何机器学习特征流水线。
架构概览
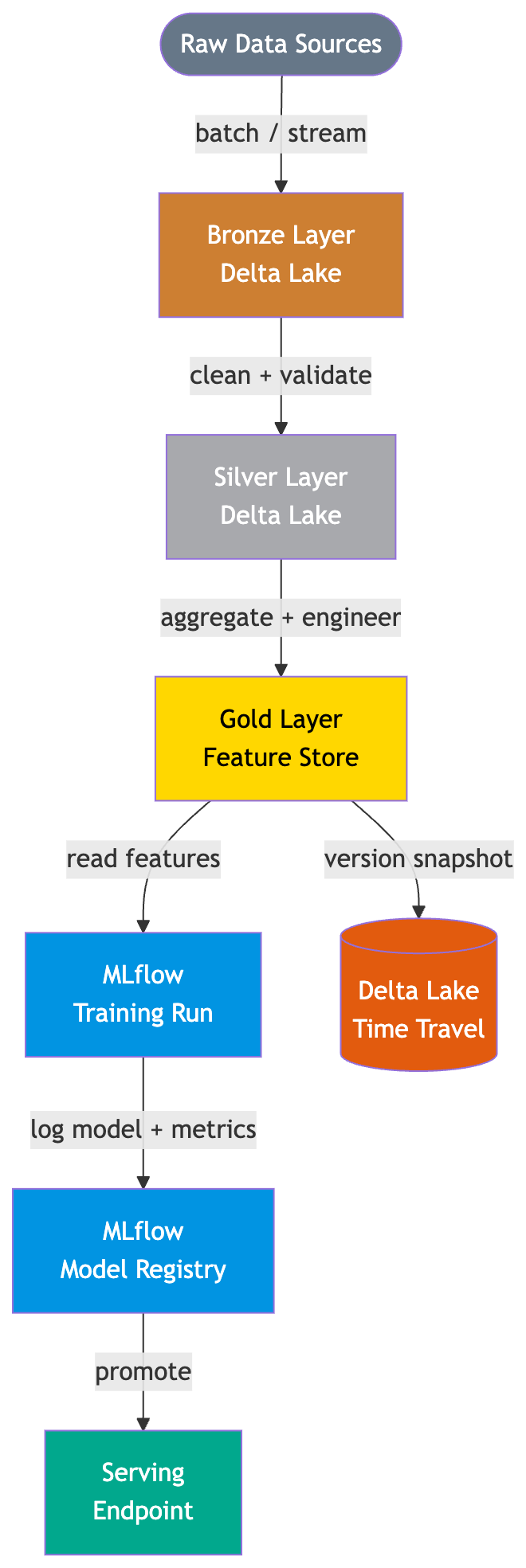
该流水线遵循 勋章架构 —— 这是一种分层方法,数据从青铜层到白银层再到黄金层的过程中,会逐步变得更加干净且更具备特征就绪状态。MLflow 横跨所有三层,追踪每一次运行。
流水线流程

层级分解
| 层级 | Delta 表 | 此处执行的操作 | 典型延迟 |
|---|---|---|---|
| 青铜层 | churn.bronze.events |
原始数据摄入,无转换,仅追加 | 分钟级 |
| 白银层 | churn.silver.customers |
去重、空值处理、模式强制 | 分钟级 |
| 黄金层 | churn.gold.features |
聚合、窗口函数、编码 | 分钟至小时级 |
| MLflow 运行 | 不适用 | 训练、指标记录、工件存储 | 小时级 |
| 注册表 | 不适用 | 版本化模型存储、阶段提升 | 按需 |
第一步 — 青铜层:原始数据摄入
青铜层仅支持追加操作。不进行任何转换。不应用任何业务逻辑。只需将数据摄入并原样保存,以便你始终可以从源头重新回放数据。