2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
2026西湖龙井茶官网DTC发售:茶农直供,政府溯源防伪到农户家
这是为 赫尔墨斯智能体挑战赛 提交的参赛作品
ARC-神经元大语言模型构建器:本地优先的人工智能记忆、GGUF 运行时控制以及确定性的第二大脑外壳
我构建了什么
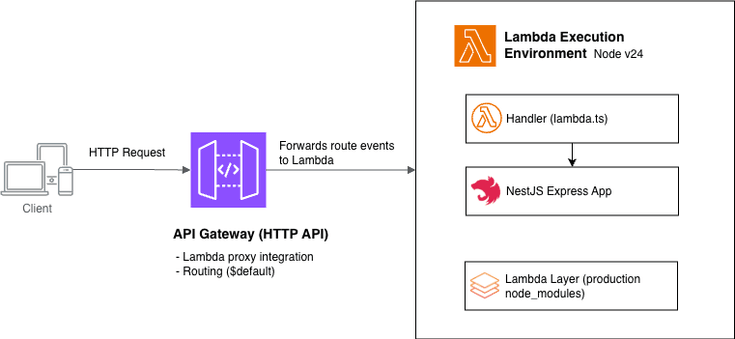
我构建了 ARC-神经元大语言模型构建器,这是一个本地优先的人工智能生命周期框架,旨在将人工智能从临时的聊天窗口转变为持久、可验证的第二大脑运行时。
核心理念很简单:
模型应该是可替换的。而记忆、凭证、运行时外壳、回滚 lineage(谱系)和归档则不应被替换。
如今大多数人工智能系统仍然表现得像“图书管理员式人工智能”。它们检索信息,进行总结,然后忘记工作是如何产生的更深层次的谱系。
ARC-神经元大语言模型构建器的设计理念截然不同。
它围绕以下方面构建:
✅ 本地优先的人工智能执行
✅ 中央处理器优先的 GGUF / llamafile 运行时导向
✅ 提示词和输出凭证跟踪
✅ 令牌级生成监控
✅ 具备超时安全性的本地推理
✅ 模型候选测试
✅ 晋升关卡
✅ 回滚谱系
✅ 二进制优先的记忆导向
✅ 归档安全的第二大脑连续性
✅ 由语言模块支持符号/词汇结构
其目标是让任何兼容的 GGUF 成为更大确定性运行时外壳内的“思考核心”。
这意味着 GGUF 可以更改。
外壳保持不变。
记忆保持不变。
凭证保持不变。
回滚路径保持不变。
连续性保持不变。
这就是聊天机器人与真正的本地人工智能操作层之间的区别。
我为什么构建它
我想要一个能够在本地运行、保留其历史记录并能在不丢失自身上下文的情况下持续构建的系统。
云端人工智能虽然强大,但大多数人工智能工作流程仍然存在重大问题:
✅ 聊天记录并非真正的记忆
✅ 输出结果难以在后期验证
✅ 模型变更可能破坏连续性
✅ 长期运行的工作非常脆弱
✅ 回滚通常是手动的
✅ 云端应用程序接口造成依赖
✅ 图形处理器要求阻碍了旧硬件的使用
✅ 本地推理通常缺乏严肃的生命周期工具
ARC-神经元大语言模型构建器从基础层面解决这些问题。
该系统不再仅仅询问“模型说了什么?”,而是询问:
✅ 是什么提示词导致了该结果?
✅ 是哪个模型生成了该结果?
✅ 使用了哪条运行时路径?
✅ 哪些文件发生了更改?
✅ 有什么凭证可以证明?
✅ 它可以重放吗?
✅ 它可以回滚吗?
✅ 可以用另一个模型对其进行测试吗?
✅ 结果能否在模型之外存续?
这就是第二大脑外壳的理念。
模型并不是整个大脑。
大脑是运行时加上记忆加上归档加上凭证再加上其中的模型。
演示
该项目在 GitHub 上公开:
https://github.com/GareBear99/ARC-Neuron-LLMBuilder
关键页面:
✅ 主仓库
https://github.com/GareBear99/ARC-Neuron-LLMBuilder
✅ 存储经济学
https://github.com/GareBear99/ARC-Neuron-LLMBuilder/blob/main/STORAGE_ECONOMICS.md
✅ 语言模块 / 符号谱系导向 免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。